Using LLMs to generate educational videos with Manim
Inspired by @karpathy’s talk that LLMs can zero-shot 3Blue1Brown-like videos by writing code in Manim, a Python library designed for creating math animations, we decided to experiment with generating Manim animations with LLMs ourselves. Through a zero-shot approach, we found that while state-of-the-art LLMS are capable of creating short animations (around 15-20 seconds), there were several issues: 1) It is far more difficult for an LLM to generate comprehensible, long-form videos that last several minutes — syntax errors in the Manim code were common, and even if the generated code was error-free, the animation itself was visually unappealing and incomprehensible. 2) A single LLM might take more than 10 minutes to produce Manim code that is free of syntax errors, even though the rendered video would only be 1 minute long. 3) Shorter animations were often visually unappealing as well.
However, with some engineering, we were able to produce higher quality, long-form videos with lower latency. We achieved this through a multi-agent system with an orchestrator agent and several worker agents operating in parallel, RAG on Manim docstrings, and multi-turn prompting (to resolve syntax errors). We’ll explore each of these techniques in greater detail below.
Ku et al. 's TheoremExplainAgent [1] also explores using LLMs to generate long-form videos with Manim and uses similar approaches such as a planner-executor agentic system, RAG, and multi-turn prompting to resolve errors. However, they report that their latency ranges from 18 to 40 minutes. Since we ultimately want users to use our tool, we have an additional latency constraint (less than five minutes).
A Multi-Agent Approach
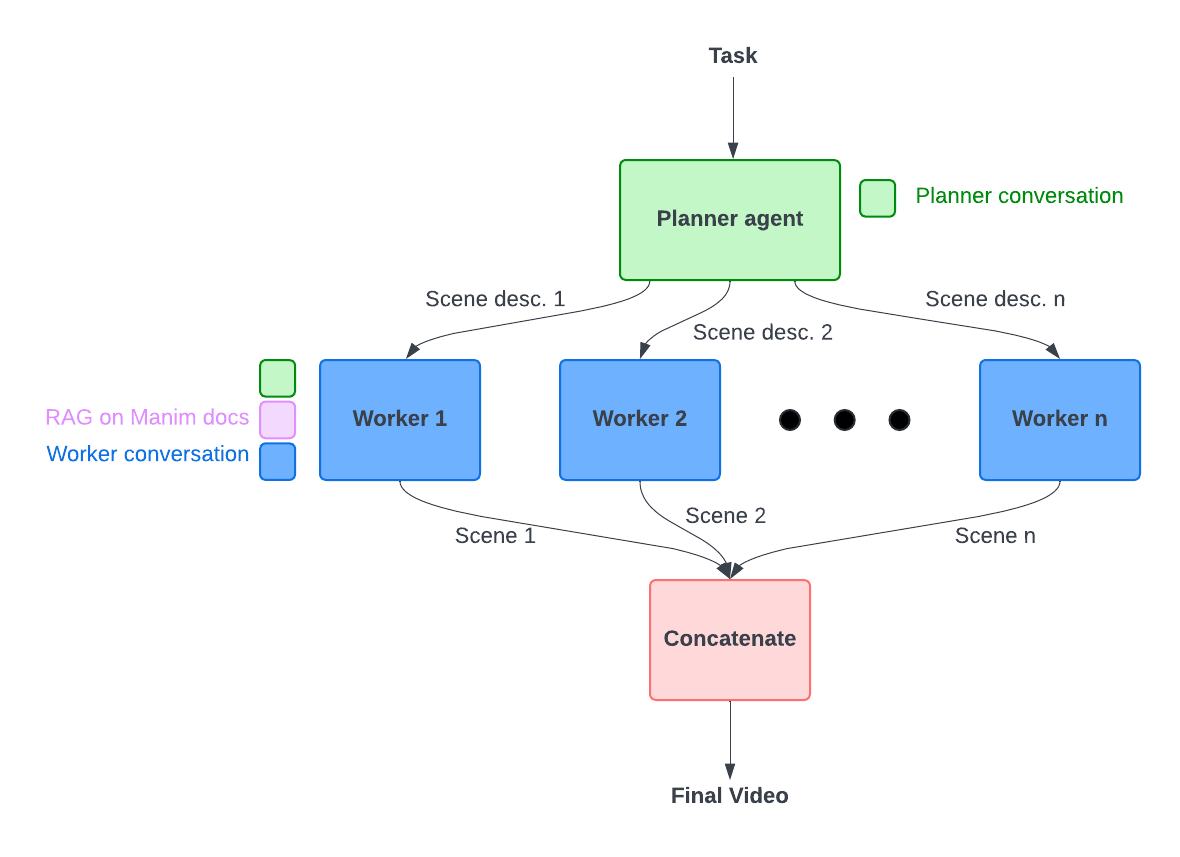
Figure 1. Manim AI Workflow
Figure 1 displays our orchestrator-worker agentic system with a planner agent and multiple executor agents. The planner agent generates a scene-by-scene description of the entire video. Then, each executor agent is responsible for generating the Manim code for a single scene. The code is extracted from each executor agent, the scene is rendered, and all scenes are concatenated to produce the final video.
We choose this approach over other approaches for several reasons. First, since we know that LLMs are more robust at generating short videos than long videos, we decide to use this orchestrator-worker approach so that each worker is only responsible for a short video. Second, instead of using a single-threaded linear agentic system, where each worker produces each scene in a sequential order to guarantee that maximum context sharing, we choose an approach in which workers operate in parallel — we sacrifice having agents have full context of the task (different workers don’t have access to each other’s reasoning traces and Manim generations) and therefore robustness [2], but we gain having lower latency due to parallelism. We ensure that each worker agent receives the full conversation history of the planner agent so that the worker has as much context as possible.
Retrieval Augmented Generation (RAG) on Manim Documentation
For each worker agent, we apply RAG by incorporating relevant sections of the Manim documentation into its context to improve its code generation capabilities. To do this, we parsed and indexed the docstrings from the Manim Github repository [3], and we provide the five most relevant Manim classes to the worker based on the description of the specific scene the worker must generate. We find that this reduces how often the LLM hallucinates Manim function calls and therefore increases the probability that the LLM generates error-free code.
Multi-Turn Prompting
Since the worker agent may generate Manim code that produces errors during runtime, we apply multi-turn prompting to ensure robustness. Specifically, if the Python runtime produces errors for our LLM-generated code, we add the LLM completion and the Python error to the context of the worker agent and re-prompt it to generate Manim code again. We set the maximum number of attempts to 5; however, we find that with our above strategy the worker agent can often produce error-free code in a single attempt.
Future Work
Currently, our multi-agent system does not “see” the actual video that it produces. In order to further improve the quality of the video, after the worker agent generates a scene, we would like to provide it with specific frames of a scene as image inputs so that it can improve upon the Manim code if there are visual issues. Additionally, we would like to add community-supported Manim plugins such as manim-physics and manim-chemistry to the context of our system to produce even better visuals.
Finally, Bleu is building an n8n-like tool so that users can produce complex agentic AI workflows with a visual editor. Instead of writing thousands of lines of Python code (as I did for this project), we would like to enable users to produce this Manim generation system simply by dragging and dropping visual components with our workflow, significantly reducing the amount of time it takes to create and deploy AI backends.
Tools used
We use the Manim Community library for animations and the Manim Voiceover plugin with Elevenlabs to add voiceovers. For code generation, we use Claude Sonnet 4.
Try it out
Try the Polymath bleuprint to generate math videos with AI.
Citations
[1] https://arxiv.org/pdf/2502.19400